千问拾音盒(原VoiceBox拾音盒重制版)B1内测
原来的VoiceBox拾音盒的模型不适用于本项目,请完全删除掉下载本项目新的模型
仅支持15.0以上系统 m芯片Mac 16G内存勉强能跑 32G内存才能体验好
原版编译环境存在很多问题,所以重新制作了一版。内置了群友提供的大量配音样本。
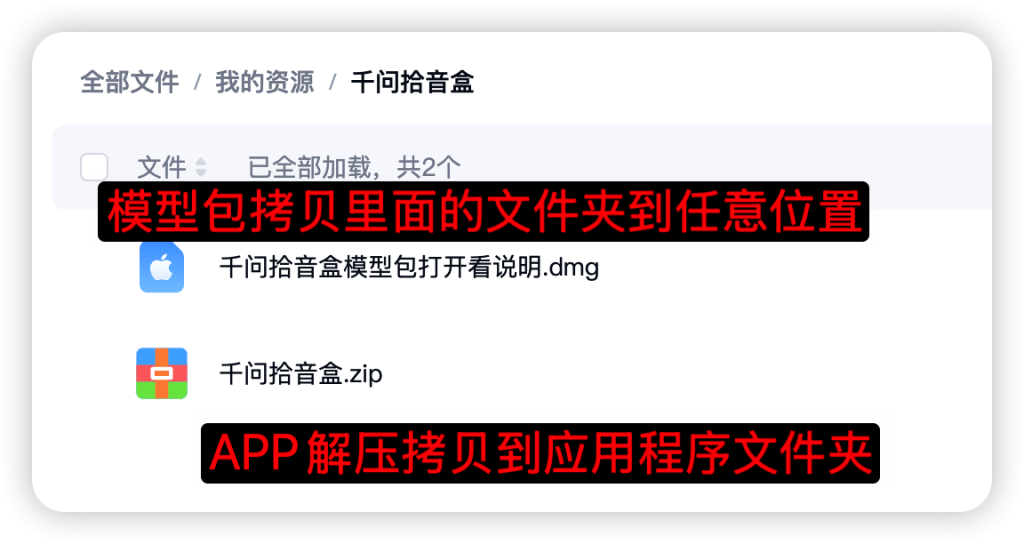
为了后续方便更新我将APP和模型包分开了,后续APP更新只需要下载APP不需要重复下载模型包了。
下载与安装
样音裁切务必保留完整语音,不要截断语音 不然输出也会被截断
样音必须提供参考文本,裁切后务必更新参考文本。
使用指南
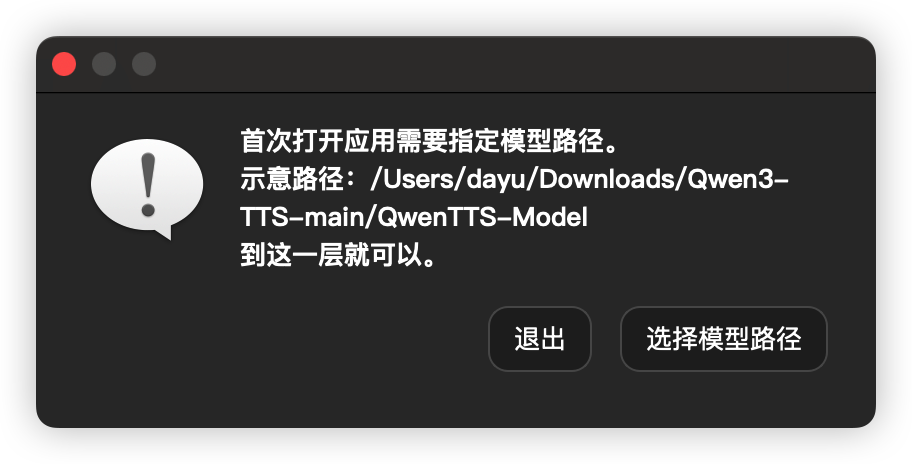
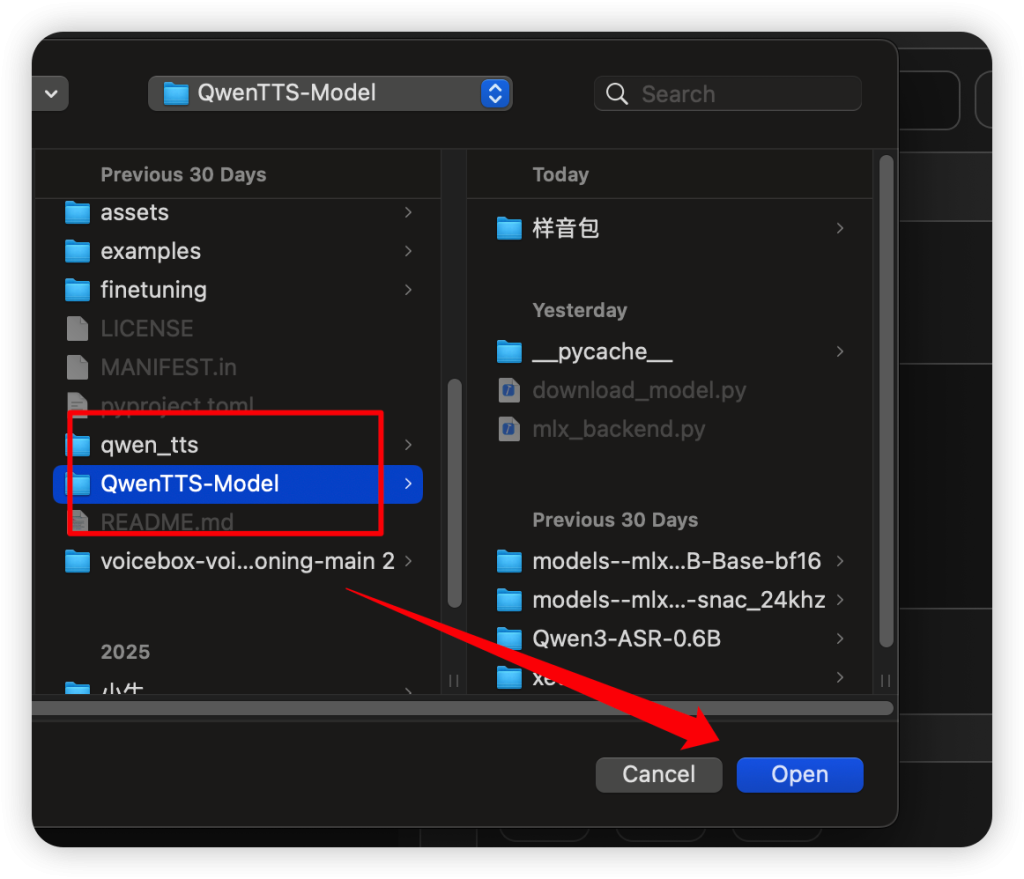
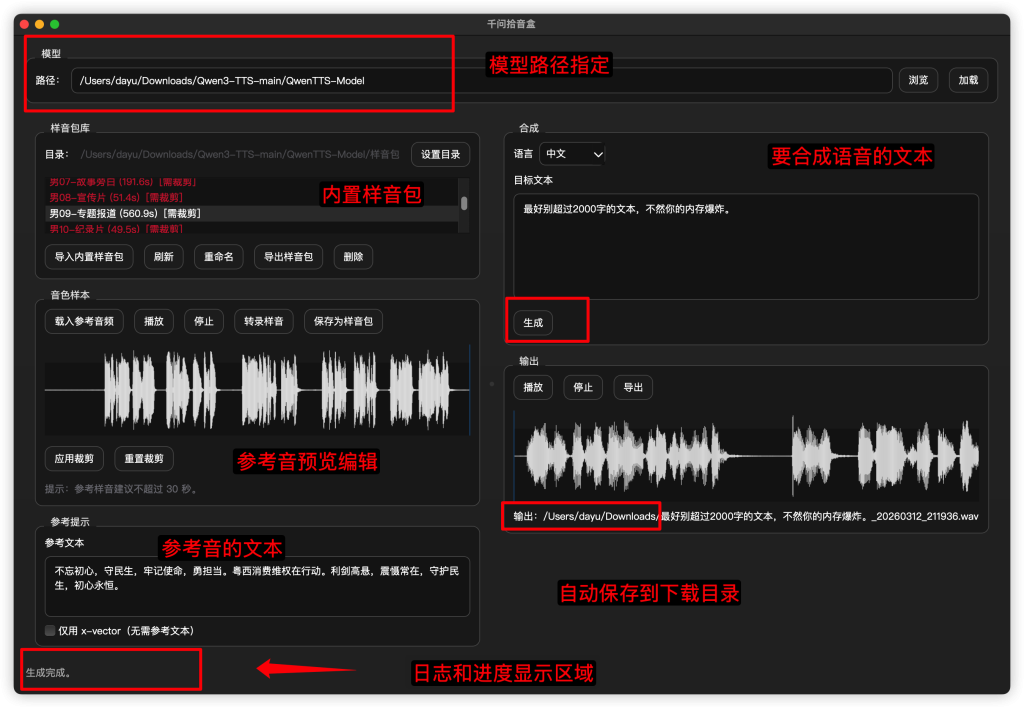
首次打开会要求指定模型路径,将上面下载的DMG包中的QwenTTS-Model文件夹拷贝到任意地方,在这里就选择你拷贝到位置,注意只需要选择到QwenTTS-Model这一层即可,不需要往下再选具体的模型。
模型中我附带了很多样音包,直接可以选用。样音由群友提供,其中有很多超长的样音,请不要直接用于语音克隆参考。点击样音后我默认有一个30秒的裁切框,点击波形图顶部移动裁切框选择你要的语气部分点击应用裁切并重新转录文本后再作为参考音。
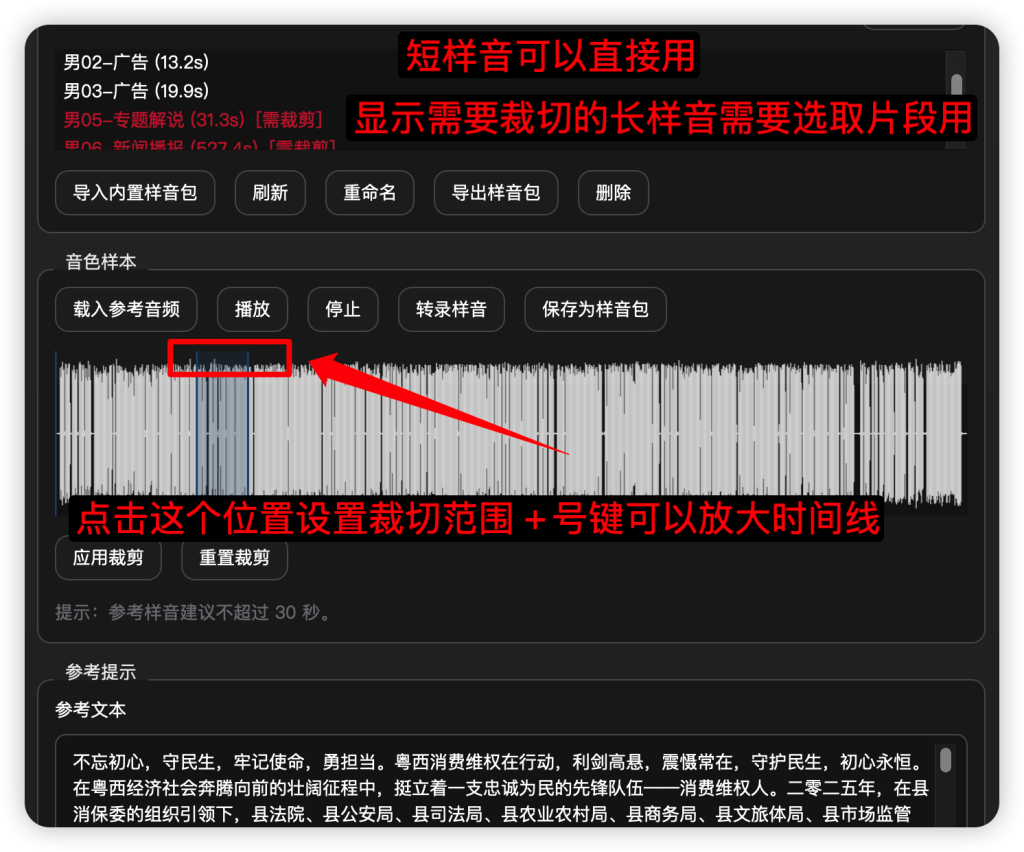
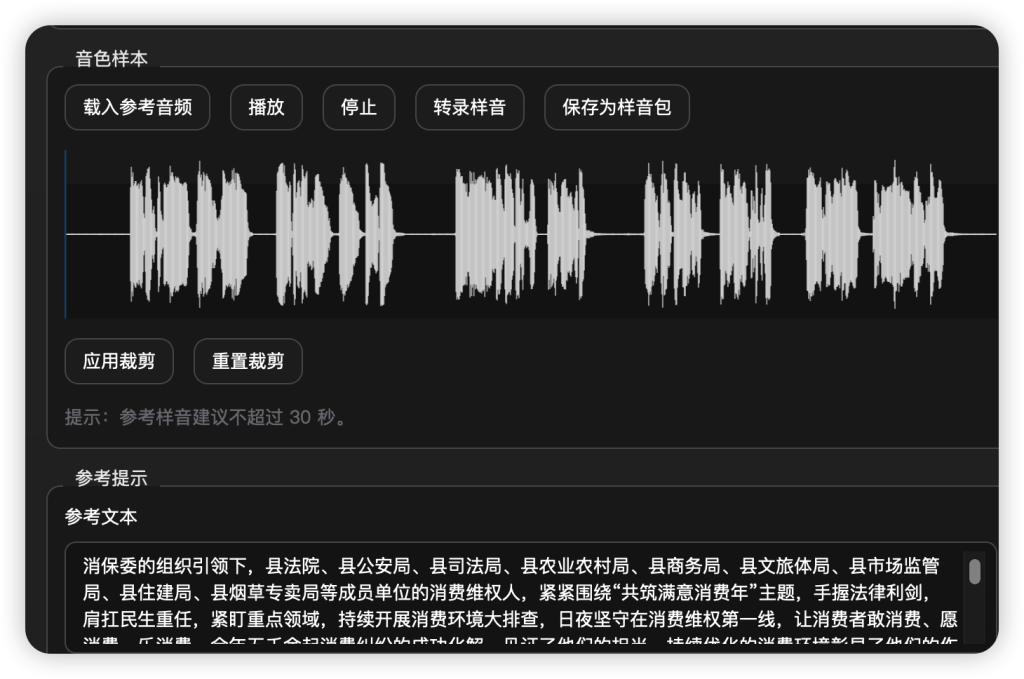
裁切注意尾巴要留完整的气口,不要从中截断,裁切范围可以左右移动的。应用裁切后注意修正参考文本,因为参考文本是整个音频的,裁切后需要重新点击“转录样音”或者手动删除多余的文本。
参考文本必须和参考音对应,如果不对应生成的语音是错乱的。参考音越长生成时间也越长,所以参考音不要超过30秒。
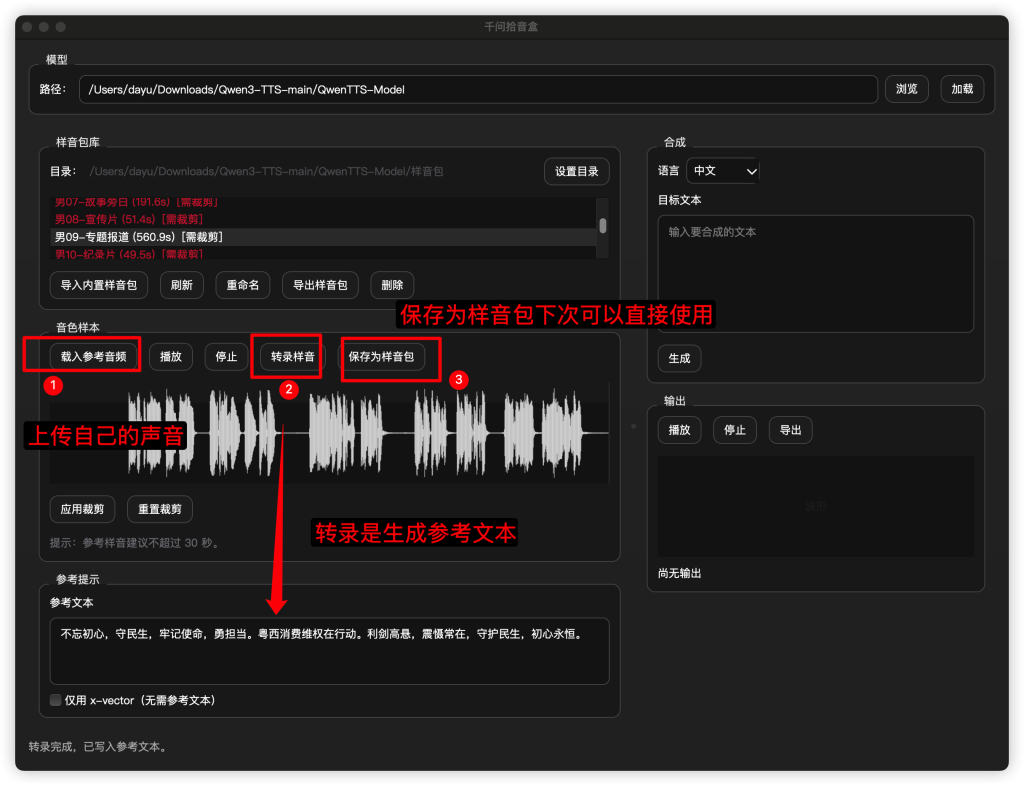
当然你也可以不用我预置的样音,按照下图的方法自己创建样音
多音字标注法
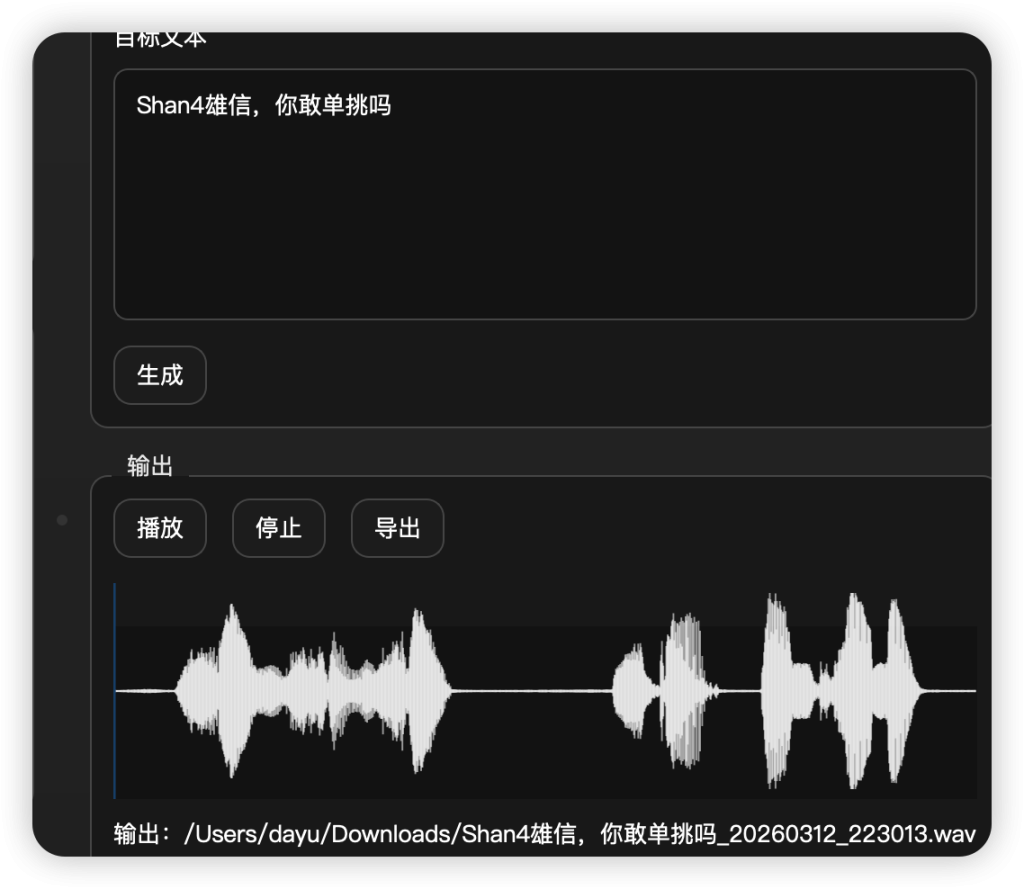
模型具有强大的上下文理解能力,常见的多音字他会根据上下文发正确的读音。人名里面可以用拼音加数字表示声调,例如(Shàn雄信,你敢单挑吗)或者(Shan4雄信,你敢单挑吗)
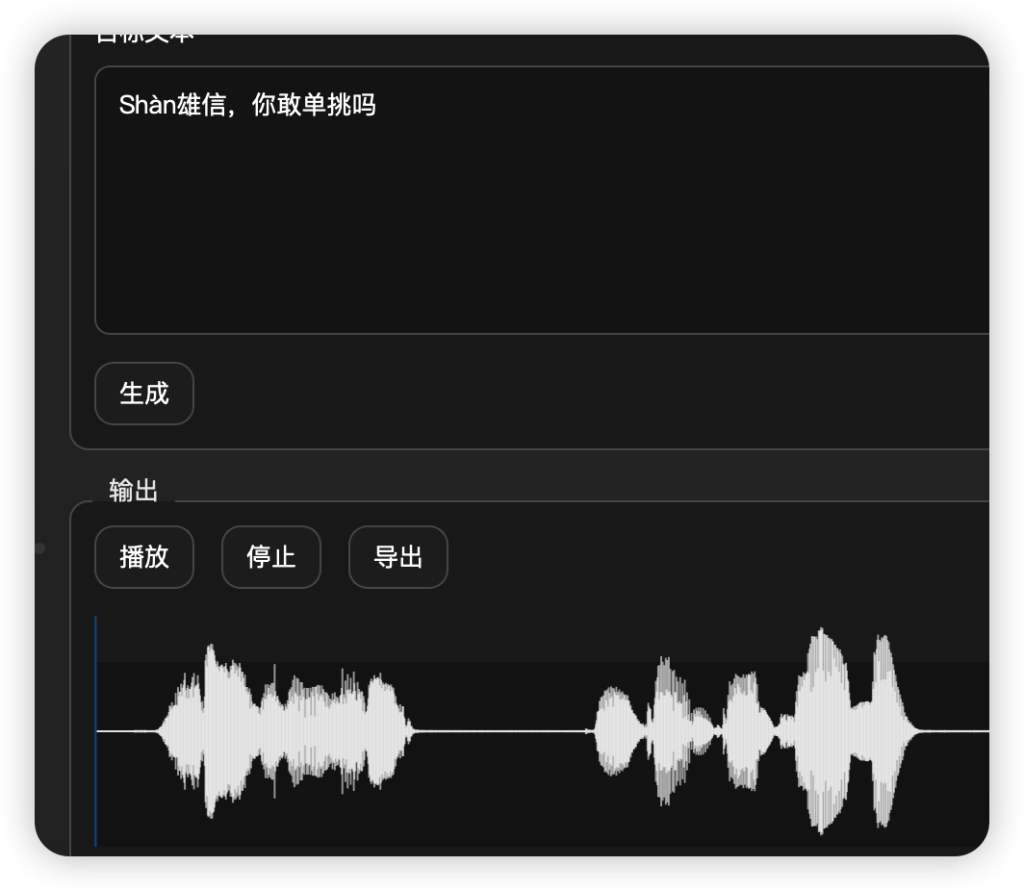
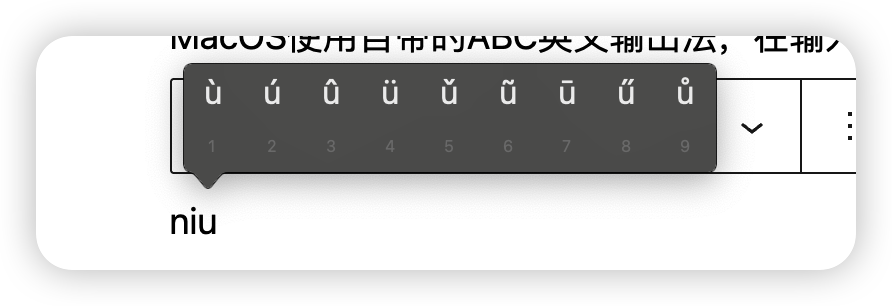
MacOS使用自带的ABC英文输出法,在输入韵母时长按就可以呼出声调菜单打出拼音音调,需要系统时区设置为中国。niúbī就是打u和i的时候长按