
FCPX字幕识别软件-Whisper大鱼重制版(开发中止)
本软件为离线本地运行,无需联网,省去了之前的字幕识别软件繁琐的API 密钥申请步骤,但是功能比较单一,只有字幕识别功能
使用方法:下载解压软件包(仅支持Apple芯片),打开后在此界面中拖入音频文件(wav、mp3),会自动触发识别进程
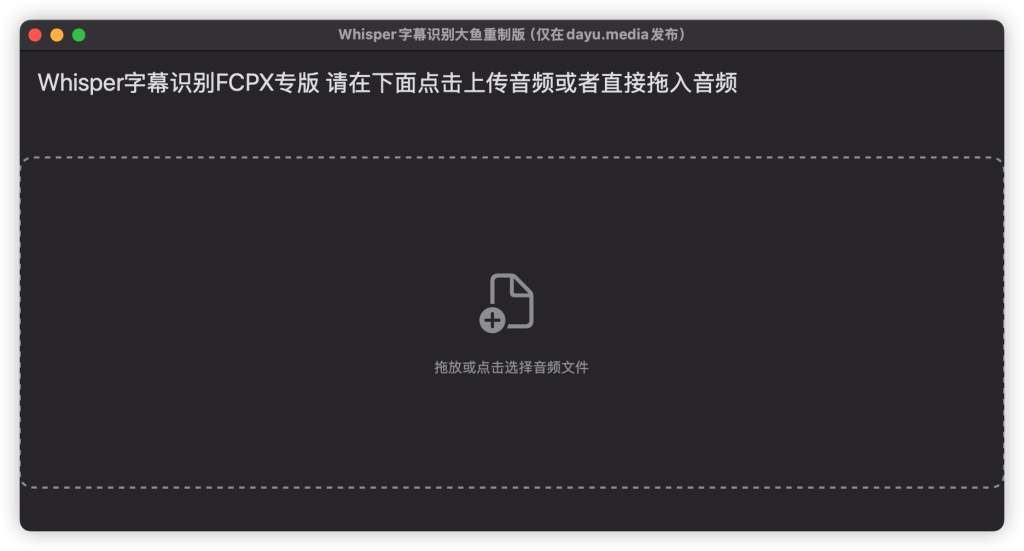
识别完成后会进入分行编辑模式,此模式只能用回车键重新分行,行首退格键与上一行合并,确定分行信息无误后点击生成字幕进入字幕编辑模式
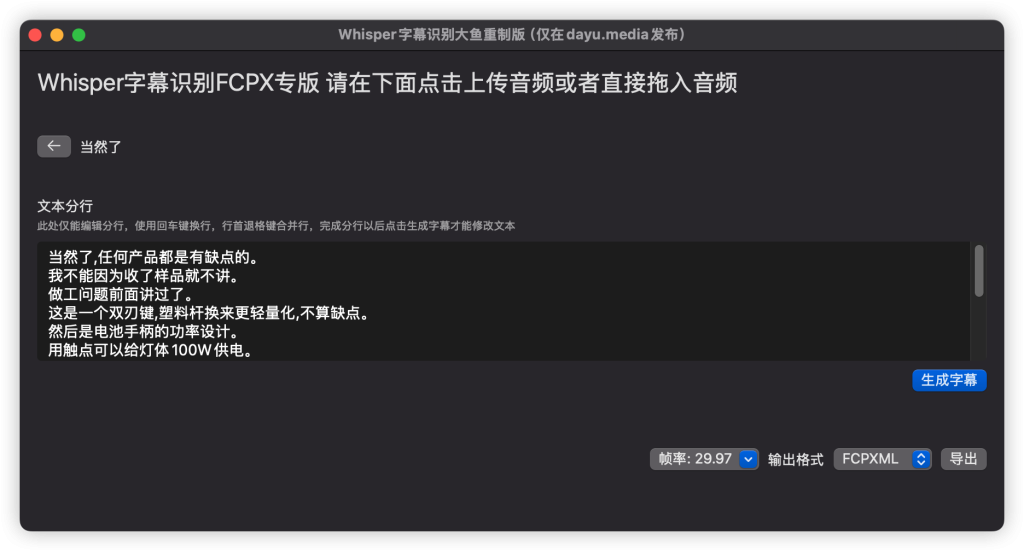
在字幕编辑模式下可以自由编辑每行字幕的文本内容,但是不能进行分行和合并行了,所以在上一步一定进行正确的分行。
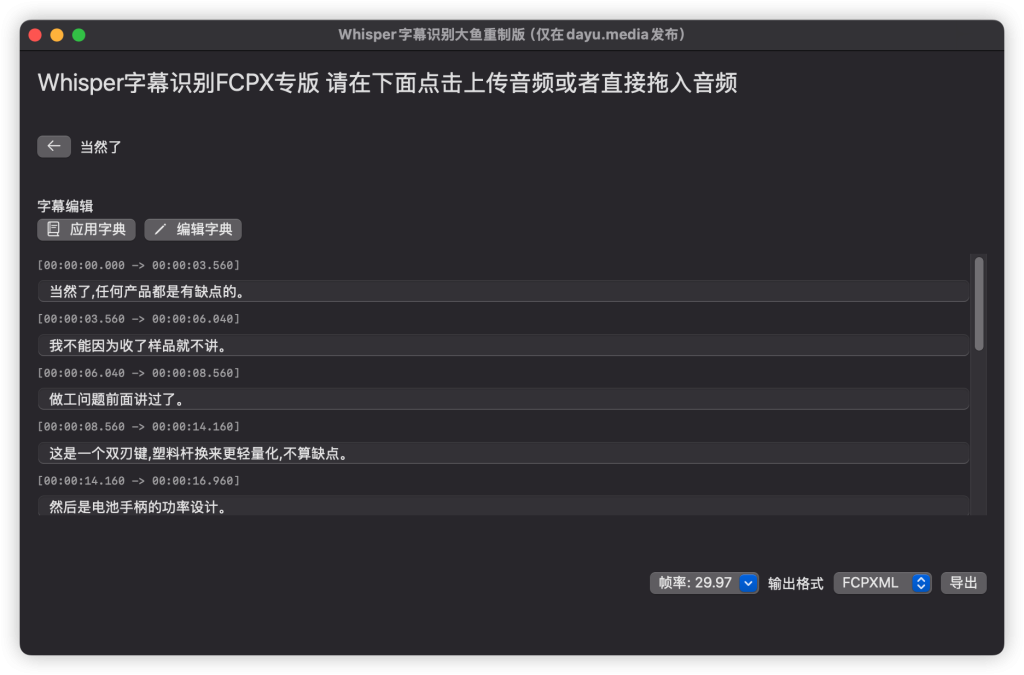
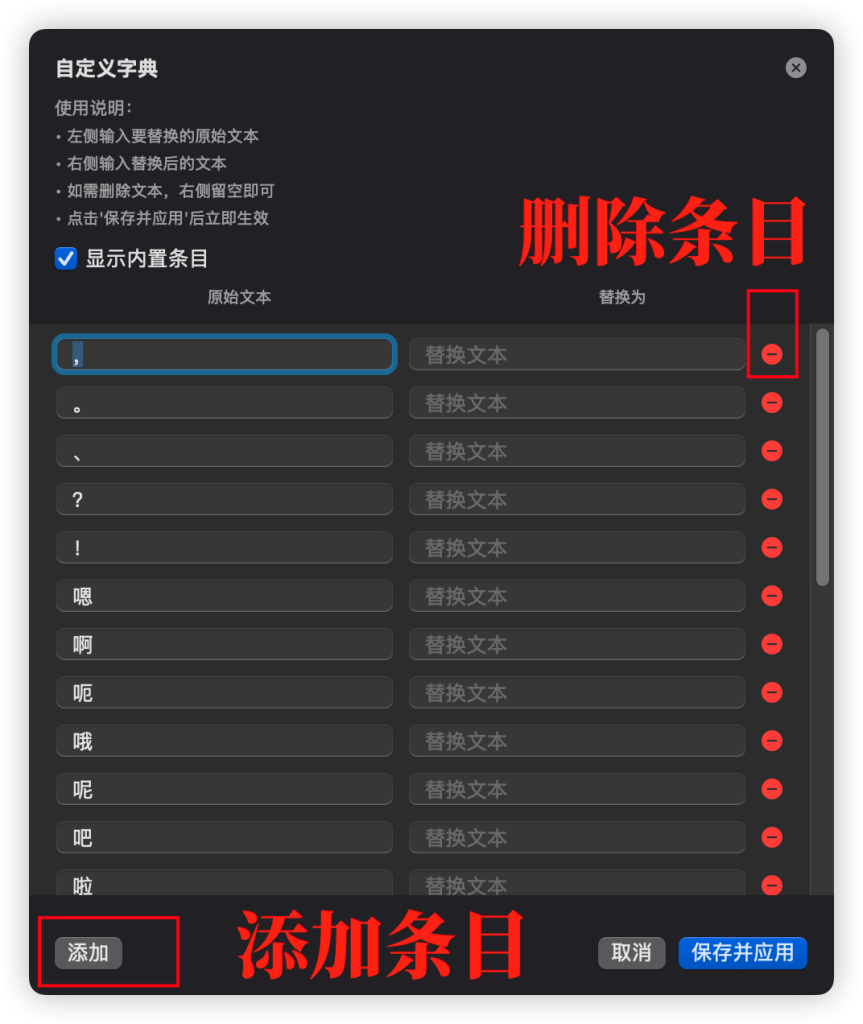
字幕编辑模式可以点击编辑字典添加批量替换文本条目,其中内置了常见的例如标点去除,语气词去除,重复词去除等,可以自行删改增加条目。保存并应用后会完成批量文本替换。
完成字幕编辑后可以导出字幕,格式可选FCPXML和SRT。注意帧率选择要和项目匹配,尤其是大部分人在相机中选择了30P或者60P,建立的项目也是30P或者60P,就没注意拍的原素材明明是29.97和59.94P,就来喷我的软件时间码不准确。
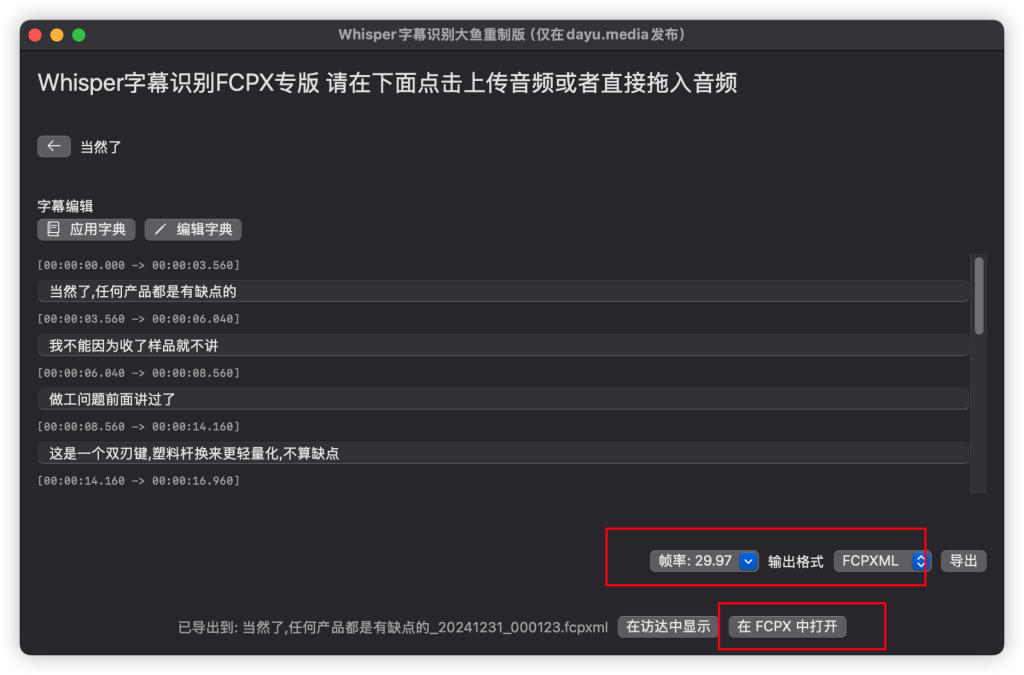
导出FCPXML后直接可以点击在FCPX中打开,会自动导入FCPX中,将导入的字幕复制到主时间线即可
通过网盘分享的文件:Whisper For FCPX大鱼重制版.zip
链接: https://pan.baidu.com/s/18HyTbHoC49weKj2USW5xhw?pwd=4tw5
已知BUG:
- 识别结果紧紧相连,停顿和静音部分没有留白。修复这个是一个巨大的挑战,我搞了两天发现后面还需要有大量的工程,所以放弃了。
- 导出的FCPXML可能含有一条红色离线音频,忽略即可,我自己电脑上没问题,不知道咋修复
以下是我修复那个巨大BUG的开发手记,希望有人能继续完成,我已经踩出一条路了,后续只要花精力是可以修复的。
1.whisper的标准输出字幕与字幕之间是紧密相连没有间隙这个应该可以从whisper.cpp源码中修改,但是这个对我来说难度太大。
2.whisper命令./whisper-cli -m 1.bin -l zh --word-thold 0.01 --output-json-full --output-words --output-txt -f jfk.wav是可以输出包含词级时间码的json文件的,词级时间码不是紧密相连的,可以从中获取到正确的间隔和留白,但是,在json中出现了词级文本乱码的问题导致json不可读取,这个发生pt模型转换成ggml模型时对于中文字符编码定义的问题,需要去修改convert-pt-to-ggml.py脚本来重新转换模型,这对于我来说更难。
3.本项目需要攻克的难题就是这个词级时间码的json解析,有了词级时间码既能方便用户手动分行获得准确时间码,也能修复字幕之间没有留白的bug
4.其他方法建议,如果不动whisper源码,也能退而求其次,根据标准输出的句子时间码平均分配到每个字符上获得字符级时间码,可以用这个时间码来保证手动分行后的时间码准确度,静音部分可以利用ffmpeg的静音检测来输出静音部分,将静音部分合并到字幕中就能修复字幕过于连续的问题了。
我自己已经开发出完美的Azrue字幕识别,所以不再对此项目进行维护



