
测试/试用链接
离线版本毕竟是少数需求,而且本地识别因为内存开销太大,容易产生漂移错误识别结果不理想,故本项目已移除本地识别逻辑。
已激活用户也可以点这个下载。
前言
本项目是在中国大陆地区诞生的第一个FCPX扩展程序,发布于2026年3月27日。从B1版本就参与内测的网友应该知道,本扩展一路走来可谓是困难重重,FCPX内部通信协议是未公开的,即使有AI的帮助,我也是经历整整半个月1000多次撞库才猜出来正确的协议规范,AI token费用就花了200美元,这一点微信群的粉丝俱有见证,整个过程我每天都会分享成果。内测版本我开放了详细的开发日志和样本提取,本来是为了让其它FCPX开发者根据样本和日志 一起来猜FCPX的内部通信协议,但是这样也就会造成其它拿来主义直接根据我的开发日志和样本进行换壳。我预料到了这个结果,但是没想到干这个事情的是一个大博主,他先是发圈否定AI生成的代码不具有独创性,给自己抄袭换壳找一个冠冕堂皇的理由,然后直接使用我之前的内测版本产生的样本文件进行替换内容,样本文件就放在插件资源包中毫不掩饰。抄就抄,我能放出开发日志和样本就不怕有人抄,你抄完还来否定别人给自己立牌子属实太恶心了。
注意事项
本程序仅在登录激活和试用期需要联网,正式激活后本地模型模式无需联网。云端识别任何时候都需要联网,请根据自己需要选择合适的模式
已知兼容MacOS26系统 FCPX11版本。理论版本支持FCPX10.6以上,MacOS14.0以上
更多版本兼容性需要更多测试,无法使用的请向我报告。
更新记录(更新版本前请删除旧版下载包和应用程序)
PB9公测
- 移除臃肿的本地识别模型,全部采用在线识别。体积由3.8G降到了48m。
- 在线识别引擎更新Qwen3-ASR-flash,移除Azrue,腾讯云升级2.0引擎,剪映火山引擎保持不变。并且千问和剪映可以直充,无需自行去申请api。
- 修复了文稿匹配分行不正确的问题。
- 增加了在线更新功能(还未测试,要下一个版本才能测试更新)
推荐自行申请API,避免被我赚差价,其中剪映火山引擎官方价格3.5/小时,用我的API我要收4元/小时,千问引擎官方价格0.7/小时,用我的API要收你 1元/小时,我是奸商,所以你自己申请API最好。
本次更新进行了大幅重构,可能会产生更多BUG,请及时向我反馈,不要闷声吃亏。
该版本首次打开会请求钥匙串访问储存设备密钥,输入开机密码后点始终允许。
PB8公测
修复字幕位置拖回时间线和预览不一致的问题,感谢微信网友“Er.大零”的反馈,但同时竖版字幕较长时不会自动换行了。如果需要竖版字数自动换行,请保存srt,在FCPX12.3以上的版本导入srt,全选srt字幕转换为翻译字幕就可以实现自动换行。
PB6公测
修复删除字幕行导致词级时间码索引失效引发全局平均时间码回退的BUG
感谢微信网友“老男孩”的反馈
PB5公测
- 增加字幕样式外宽宽度、阴影距离、模糊参数
- 修复预览位置和拖回时间线位置不统一问题。
- 更新剪映引擎设置,兼容火山引擎新版本API规范
PB2公测
- 完全修复文稿匹配模式因为标点占位问题导致的吞字错字。
- 增加字幕样式表面、外框、阴影颜色设置(目前只撞出了颜色字段,宽度距离等参数还没有撞出来,请等待后续更新)
- 增加竖屏项目自动转换预览和字幕自动换行
PB1公测
- 修复字幕分行、合并行编辑偶尔会光标跳转到首行的问题
- 修复某些情况下回退到全局平均时间码导致时间码准确度极低的问题
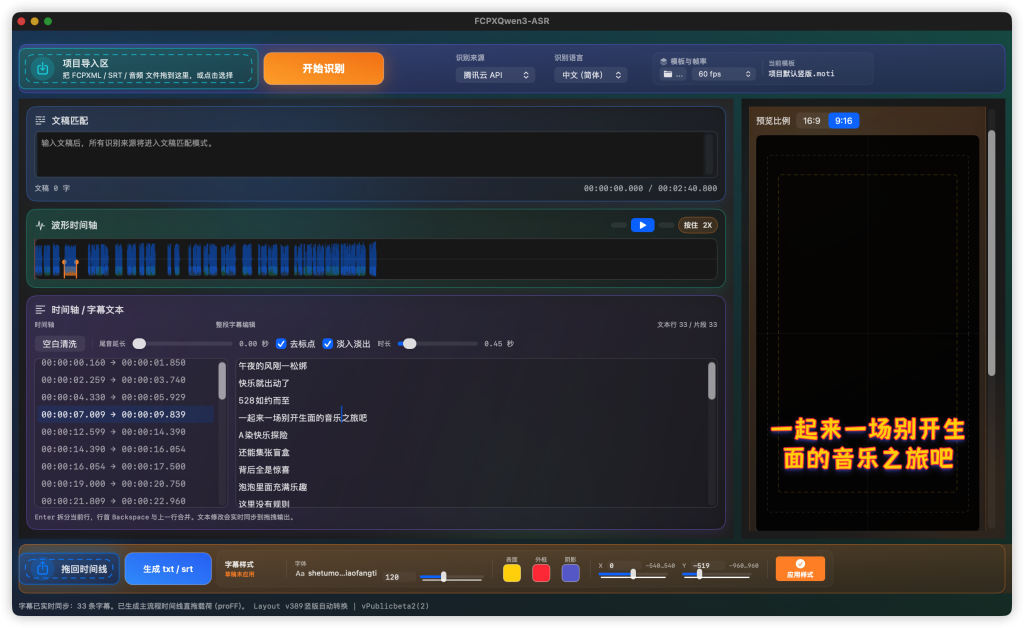
- 增加自动保存SRT的功能。在识别完成、编辑校对字幕、应用词典后都后自动保存srt,二次更改无需重新识别。自动保存路径为:“影片-FCPX千问识音临时输出字幕文件夹”,如遇FCPX意外中止,可以将srt导入扩展继续之前的校对工作。
- 大幅简化音频波形渲染,减少长音频滚动时的卡顿。这会导致鼠标滚轮放大时间线只能看到简易的音量标记,性能和精确度只能二选一。
- 感谢微信网友 “老男孩”的测试反馈
B10内测
- 修复长音频自动分段识别后拼接错误出现重复文本的问题。
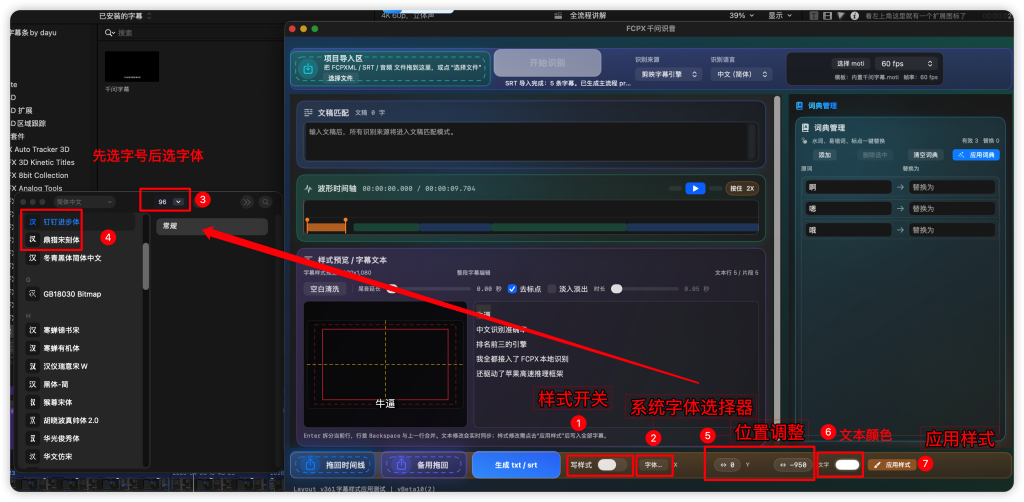
- 增加字体、字号、位置、文本颜色的设置
B9内测
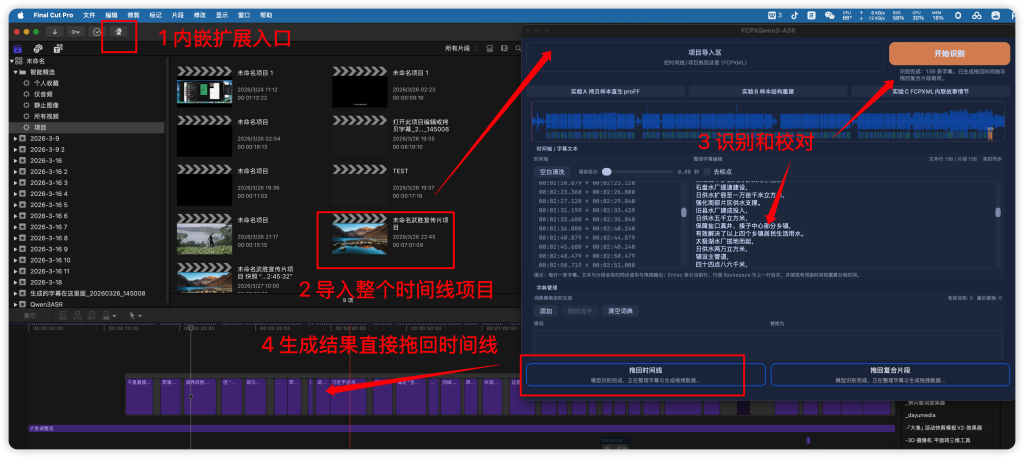
- 经历1039次盲猜和撞库,终于打通FCPX和扩展之间的私有通信协议规范,实现了将生成结果以故事情节的方式拖回时间线。
- 修复界面第一次打开显示不全需要手拉的问题。
- 修复从分享“将音频发送到千问识音”导入的音频不能自动识别帧速率的问题。
由于B9的拖回算法变了,所以字体字号设置又失效了
B8内测
- 增加文稿匹配模式
- 修复字体字号应用失效的问题
已知问题:新增的导出音频到扩展需要严格设置帧速率和项目一样,不一致会导致复合片段无法解包。下个版本我会增加自动识别项目帧速率设置
B7内测
- 刷新试用时间
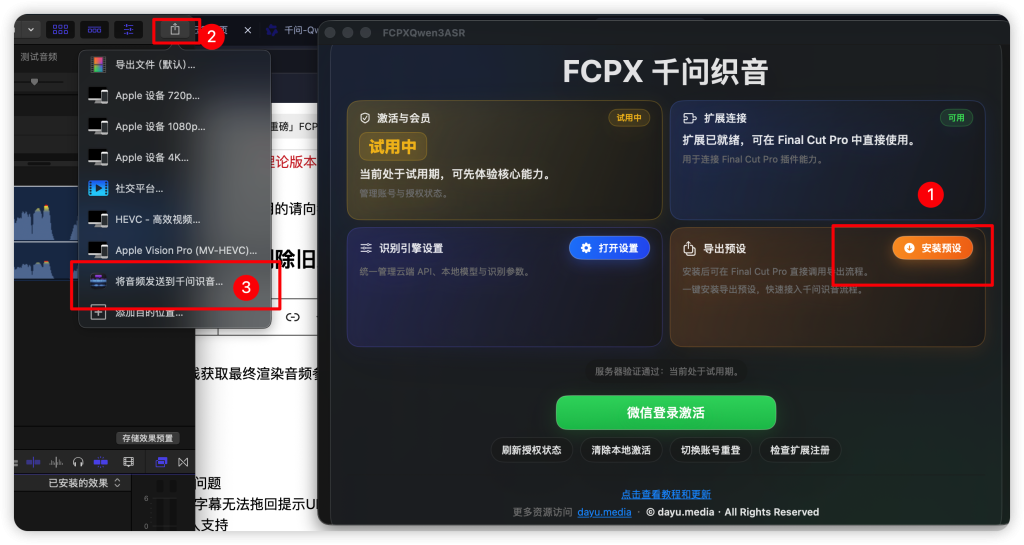
- 增加一键从FCPX时间线获取最终渲染音频参与识别。
- 优化UI界面
- 新增专为超长字幕优化的拖回复合片段,避免超长时间线字幕拖回失败。
B6内测
- 修复浅色模式UI异常的问题
- 修复超长时间线生成的字幕无法拖回提示UID:8192超出范围的问题
- 增加srt/音频文件的导入支持
- 增加srt/txt文件生成,自动保存在“影片-FCPX千问识音临时输出字幕文件夹”
B5内测(本次UI重绘是在MacOS深色模式下进行的,导致浅色模式下看不清界面,等待修复)
- 界面UI重绘 彻底修复试用状态异常问题 本次内测会刷新使用状态,已过期用户可以继续试用
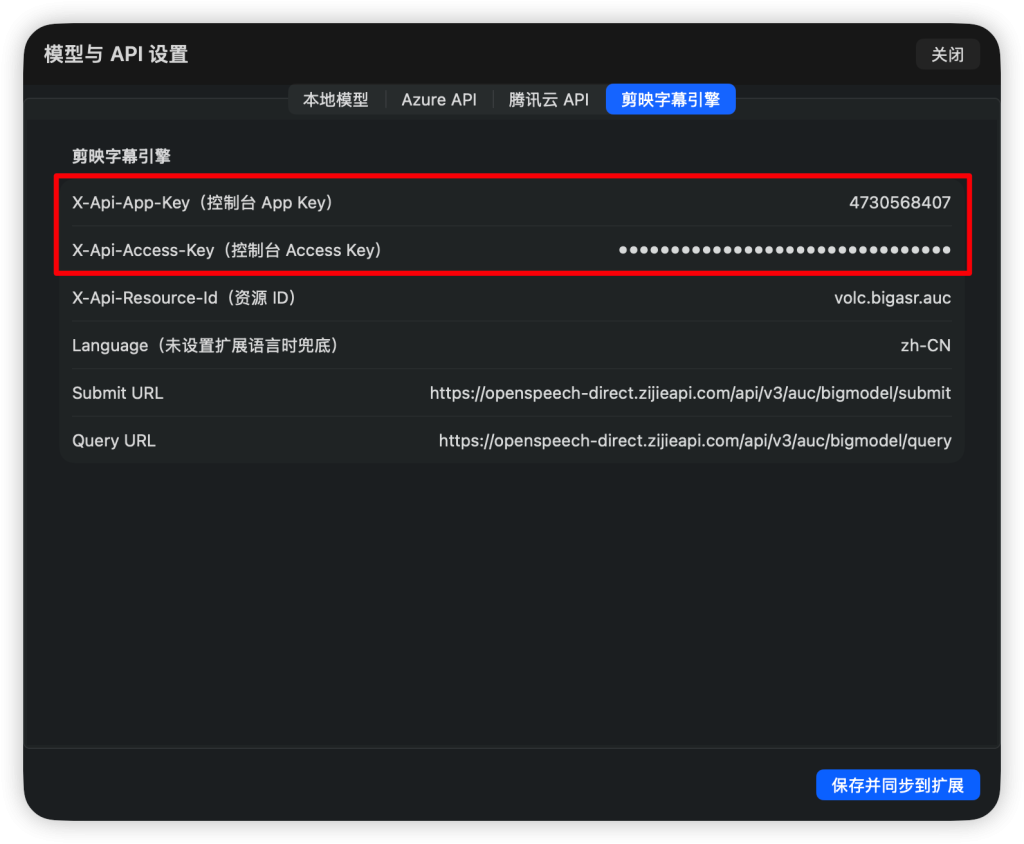
- 接入剪映字幕识别引擎-火山引擎豆包录音文件识别。开通免费额度领取地址https://console.volcengine.com/home(20小时额度90天有效期)正式调用3.5元/小时。具体流程请询问豆包。将获取到的key填入设置页面中即可使用剪映字幕引擎。开通后到https://console.volcengine.com/speech/service/10012复制App Key和Access Key填入设置页面。
B4内测
- 修复试用状态异常问题
- 修复界面发灰问题
- 修复登错账号无法换号登录的问题
B3内测
关闭字幕默认的淡入淡出效果,改为扩展开关
B2内测
- 加入更高精度本地大模型(0.6Bbf16精度/1.7Bbf16精度)推荐32G内存以上使用高精度模型
- 加入微软Azrue 云端识别接口 key申请方式请参考历史贴大鱼自制免费 AI 配音+字幕识别+SRT转FCPXML软件(12.28更新)-免费资源 https://dayu.media/1491/ (需要Visa/master信用卡 免费)
- 加入腾讯云端语音识别API接口(每月免费10小时额度),API申请地址https://console.cloud.tencent.com/asr 请注意生成的key只显示一次,务必下载csv保存到本地
- 增加切换登录账号避免登录错误
- 改进音频渲染逻辑,避免渲染结果和时间线不一致。(可能还是存在问题 需要更多测试反馈)
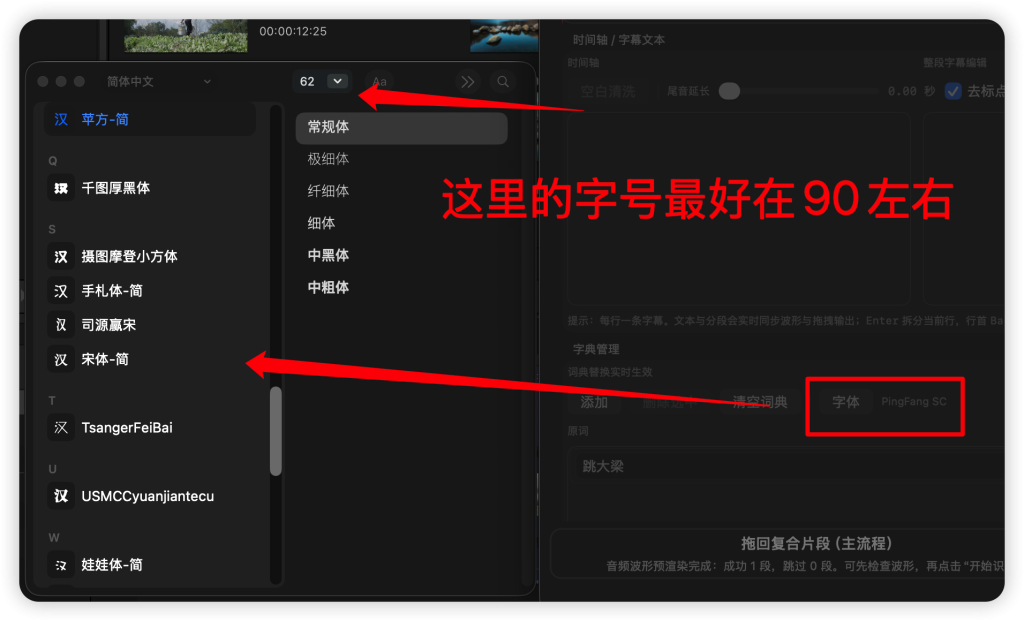
- 加入字体字号指定、moti字幕文件指定
后续还会增加阿里百炼云/火山引擎豆包云端识别模型,正在和服务商沟通落地方案
软件特色
对比mCaptionsAI,本软件有以下优势
mCaptions使用的whisper模型,存在着字幕之间没有静音间隔和偶尔输出繁体字幕的通病。千问织音使用Qwen3-ASR大模型,是目前本地部署对中文支持最好的大模型,也是Mac下面最快的模型,在中文识别的准确度和速度方面全方面碾压whisper。
mCaptionsAI是DesignStudio的附属程序,必须要安装整个高达16GB的DesignStudio包和2GB的whisper模型包,还不能删减不需要的文件。由于严格的文件完整性检查,很容易误操作动了文件导致激活失效需要重新激活。FCPX千问织音整个程序+模型只有3GB,使用简单的微信登录激活,不会出现中途激活失败的情况。
mCaptionsAI输出的字幕不能重新分行、校对,需要拖回时间线后再FCPX分行,体验极差。FCPX千问织音可以在扩展中对生成的字幕进行重新分行、合并行、批量替换错字、语气词、调整字幕时间,最后再拖回时间线,拖回后几乎不需要再次校正。
咱们国产软件,也是能吊打美国佬的
(特朗普 我****)
使用教程
测试版主要是为了验证功能性和流程和照顾低配电脑性能开销,我内置的是精度比较低的0.6B 4bit模型,16G内存就能运行,但是识别准确率比较低,后续我会补充更高精度的bf16精度和更高的1.7B参数,对低配电脑增加云端识别来提升准确度。
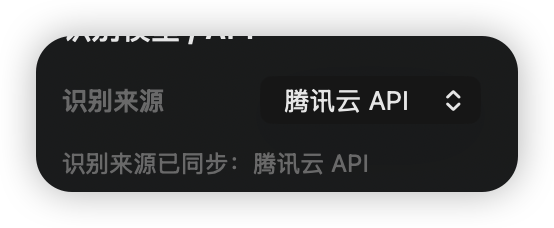
(已增加,按下图设置)
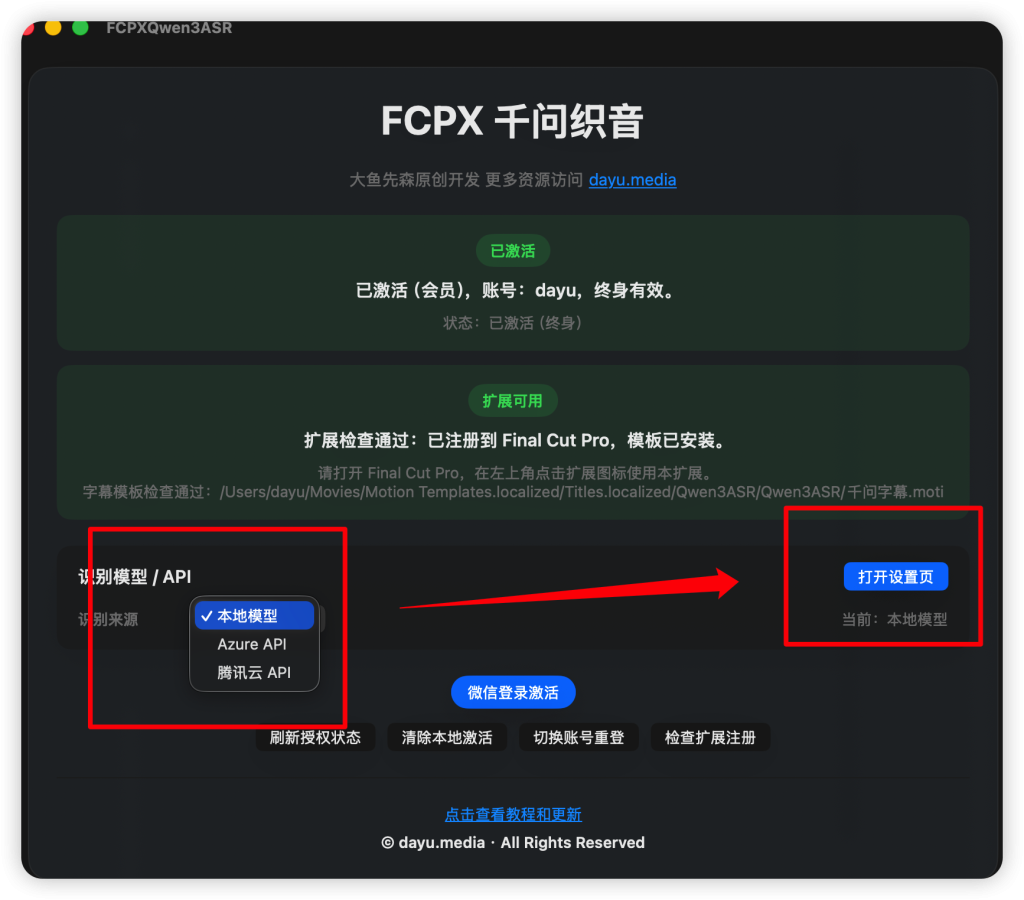
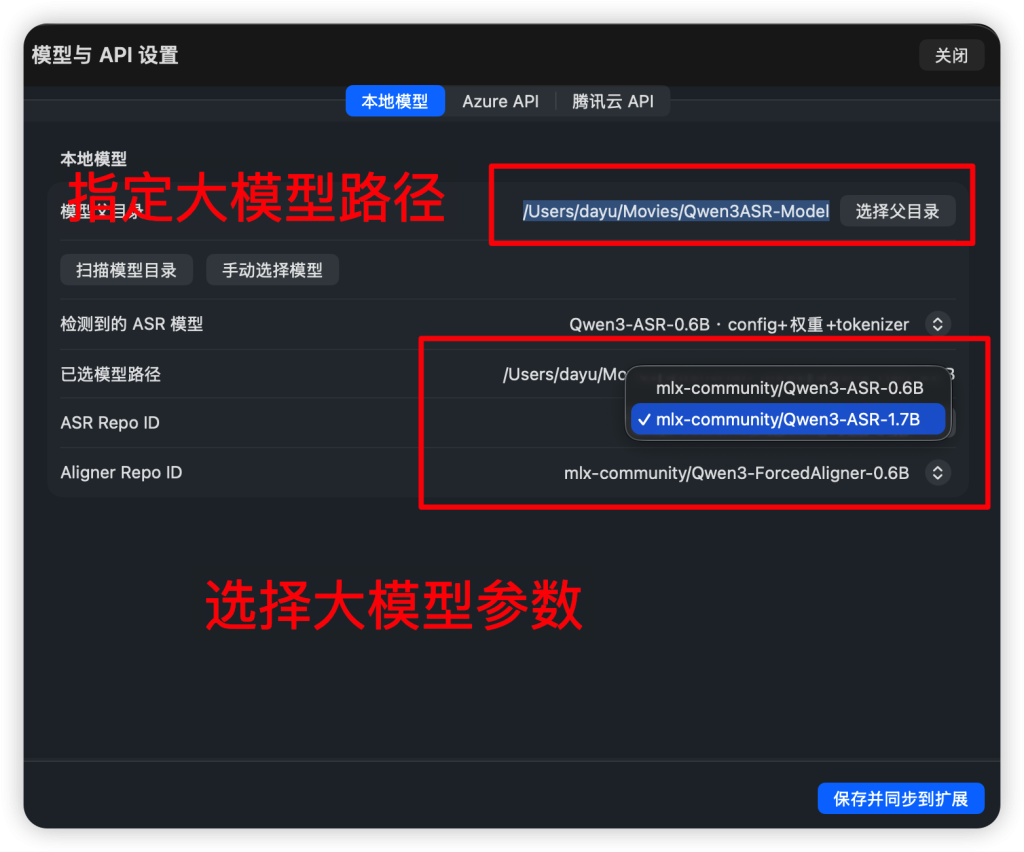
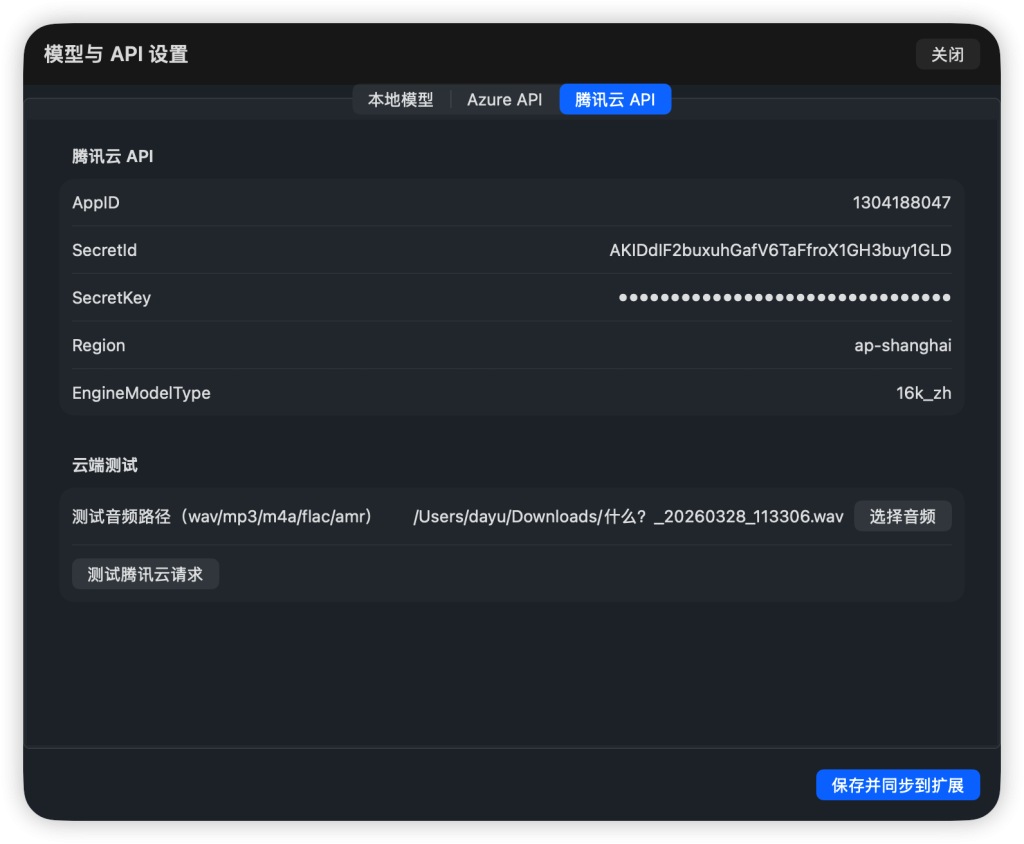
如果你申请了腾讯云语音识别API,请再在此填入,并使用本地音频测试是否连通。腾讯云API申请地址https://console.cloud.tencent.com/asr (免费,微信登录即可)
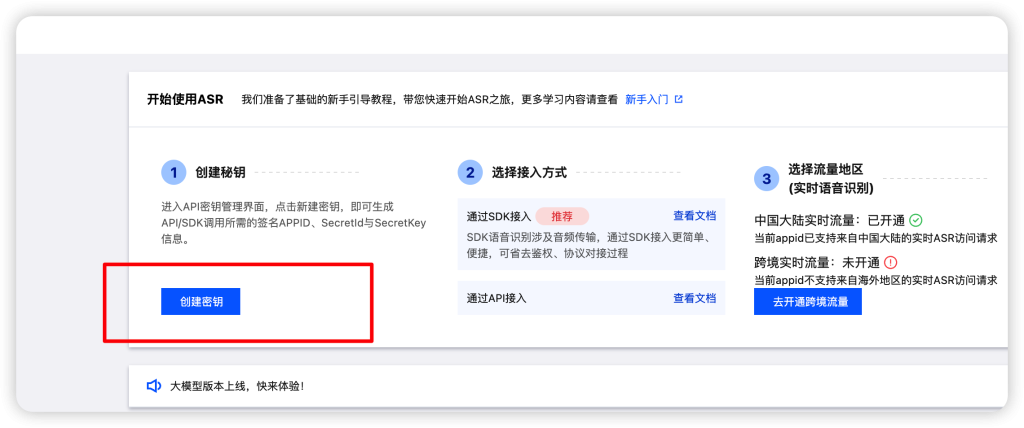
测试流程
本软件有1天试用期,所有人都可以参与内测
下载后打开DMG 将APP拖入应用程序或者拷贝到任意位置,打开一次自动注册FCPX扩展,然后在FCPX左上角点击扩展图标就可以在FCPX中打开扩展
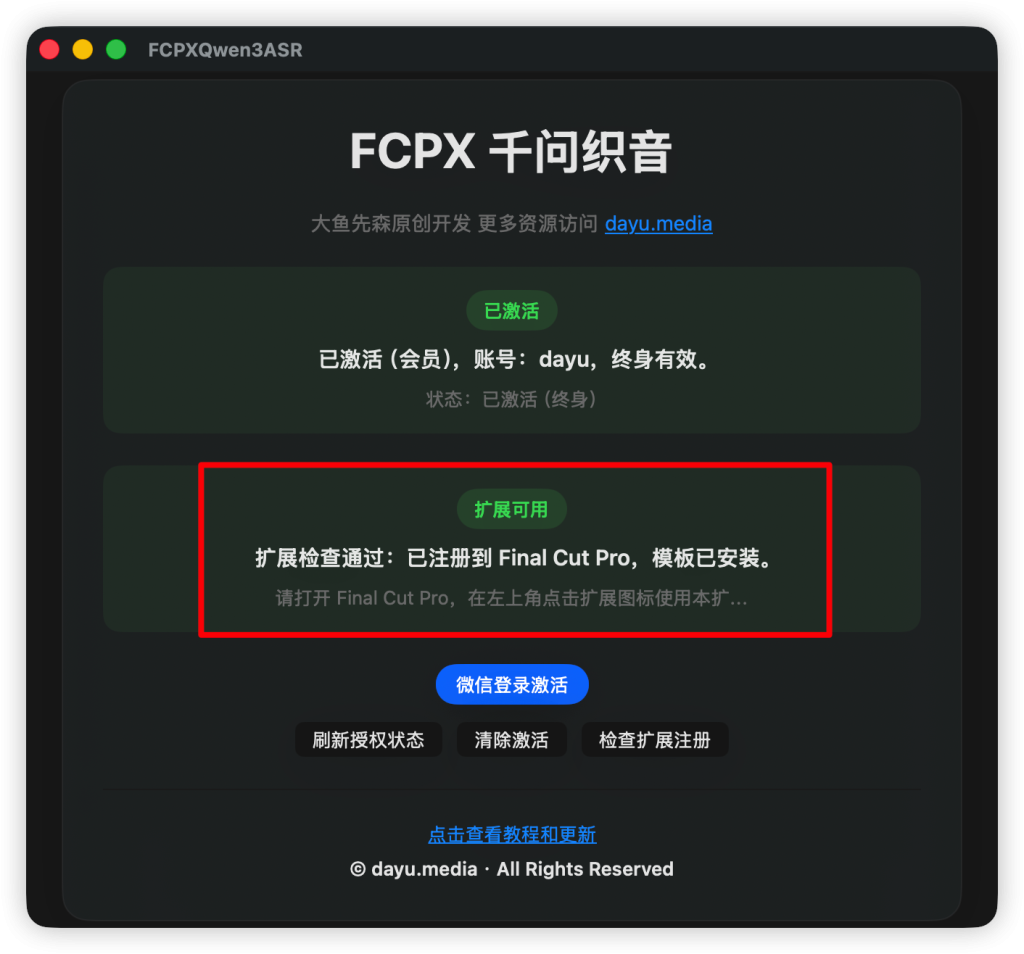
如果试用结束你觉得还行的话,可以在文章右侧购买在主APP中微信登录激活即可,会员直接在主APP中登录激活。
在试用过程中遇到任何问题,请将下载目录的“FCPX千问织音”文件夹打包发给我,微信:Dayumedia2
已知问题
第一次打开扩展可能会界面显示不全,手动按住四角边缘拖拽到显示全部界面即可,下一次打开就会记住窗口布局。这个界面发灰和尺寸不自动适应问题后续会修复。
本地推理全靠显卡和GPU运算,不要拖太长的项目进去识别,(5分钟以内最佳,超出5分钟会分批次自动裁剪识别避免内存不够)长项目请在主APP中选择识别来源为腾讯云API。
界面中实验ABC和拖回复合片段按钮是开发测试接口,对用户没有用,本项目还没有开发完毕所以接口先留着,后续正式版会移除。



能不能发一下剪映的api怎么弄啊,各种弄都是错误
FCP 12.2发送至千问识音没反应
怎么删除这个留言啊,解决好了😂没有问题
拖入后总提示重新打开扩展程序怎么回事
最新版本是哪个版号?
请问试用的时候生成出来的字幕都是乱的,生成的时候还老是提示时间码错误是什么原因
「已解决」经查实是用户用于测试的音频太长了内存爆了,本地模型无法完成推理。同时因为测试音频噪音巨大还有背景音乐,导致人声识别不理想
添加右侧微信 我远程看看
‘’
一次付费后面都可以一直使用么,可以用几台设备啊!
永久,两台设备,可以自行解绑换机